Why SCOPE-RL?
End-to-end implementation of Offline RL and OPE
Variety of OPE estimators and standardized evaluation protocol of OPE
Provide Cumulative Distribution OPE for risk function estimation
Validate potential risks of OPS in deploying poor policies
Try SCOPE-RL in two lines of code!
- Compare policy performance via OPE
# initialize the OPE class
ope = OPE(
logged_dataset=logged_dataset,
ope_estimators=[DM(), TIS(), PDIS(), DR()],
)
# conduct OPE and visualize the result
ope.visualize_off_policy_estimates(
input_dict,
random_state=random_state,
sharey=True,
)
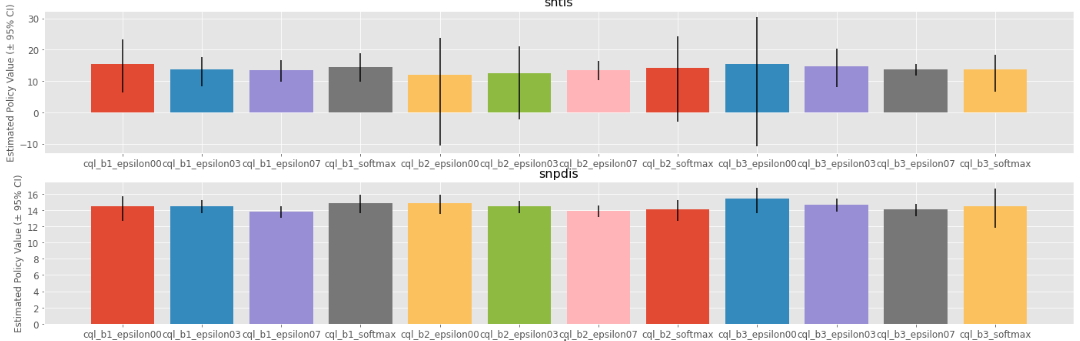
Policy Value Estimated by OPE Estimators
- Compare cumulative distribution function (CDF) via OPE
# initialize the OPE class
cd_ope = CumulativeDistributionOPE(
logged_dataset=logged_dataset,
ope_estimators=[
CD_DM(estimator_name="cdf_dm"),
CD_IS(estimator_name="cdf_is"),
CD_DR(estimator_name="cdf_dr"),
CD_SNIS(estimator_name="cdf_snis"),
CD_SNDR(estimator_name="cdf_sndr"),
],
)
# estimate and visualize cumulative distribution function
cd_ope.visualize_cumulative_distribution_function(input_dict, n_cols=4)

Cumulative Distribution Function Estimated by OPE Estimators
- Validate top-k performance and risks of OPS
# Initialize the OPS class
ops = OffPolicySelection(
ope=ope,
cumulative_distribution_ope=cd_ope,
)
# visualize the top k deployment result
ops.visualize_topk_lower_quartile_selected_by_cumulative_distribution_ope(
input_dict=input_dict,
ope_alpha=0.10,
safety_threshold=9.0,
)
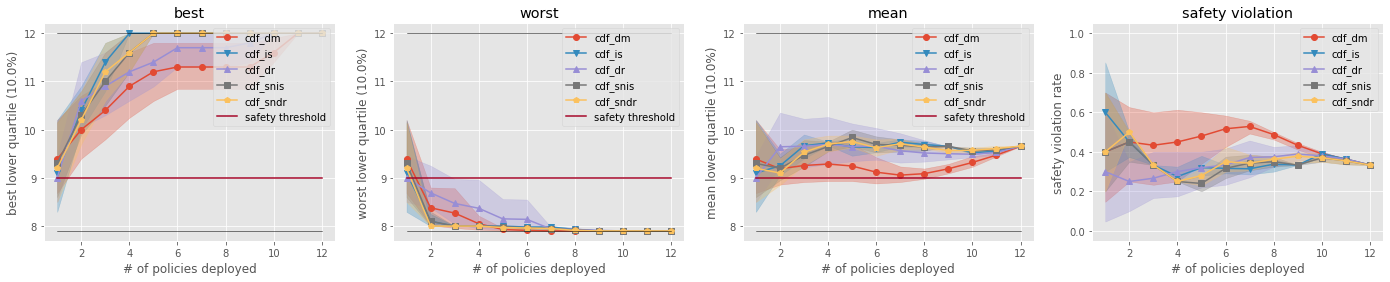
Comparison of the Top-k Statistics of 10% Lower Quartile of Policy Value
- Understand the trend of estimation errors
# Initialize the OPS class
ops = OffPolicySelection(
ope=ope,
cumulative_distribution_ope=cd_ope,
)
# visualize the OPS results with the ground-truth metrics
ops.visualize_variance_for_validation(
input_dict,
share_axes=True,
)

Validation of Estimated and Ground-truth Variance of Policy Value
Explore more with SCOPE-RL
Citation
If you use our pipeline in your work, please cite our paper below.
Haruka Kiyohara, Ren Kishimoto, Kosuke Kawakami, Ken Kobayashi, Kazuhide Nakata, Yuta Saito.
SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation
@article{kiyohara2023scope,
title={SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation},
author={Kiyohara, Haruka and Kishimoto, Ren and Kawakami, Kosuke and Kobayashi, Ken and Nakata, Kazuhide and Saito, Yuta},
journal={arXiv preprint arXiv:2311.18206},
year={2023}
}
Join us!
Any contributions to SCOPE-RL are more than welcome!
If you have any questions, feel free to contact: hk844@cornell.edu