SCOPE-RL#
A Python library for offline reinforcement learning, off-policy evaluation, and selection
Overview#
SCOPE-RL is an open-source Python library designed for both Offline Reinforcement Learning (RL) and Off-Policy Evaluation and Selection (OPE/OPS). This library is intended to streamline offline RL research by providing an easy, flexible, and reliable platform for conducting experiments. It also offers straightforward implementations for practitioners. SCOPE-RL incorporates a series of modules that allow for synthetic dataset generation, dataset preprocessing, and the conducting and evaluation of OPE/OPS.
SCOPE-RL can be used in any RL environment that has an interface similar to OpenAI Gym or Gymnasium-like interface. The library is also compatible with d3rlpy which implements both online and offline RL methods.
Our software facilitates implementation, evaluation and algorithm comparison related to the following research topics:

workflow of offline RL, OPE, and online A/B testing
- Offline Reinforcement Learning:
Offline RL aims to train a new policy from only offline logged data collected by a behavior policy. SCOPE-RL enables a flexible experiment using customized datasets on diverse environments collected by various behavior policies.
- Off-Policy Evaluation:
OPE aims to evaluate the performance of a counterfactual policy using only offline logged data. SCOPE-RL supports implementations of a range of OPE estimators and streamlines the experimental procedure to evaluate the accuracy of OPE estimators.
- Off-Policy Selection:
OPS aims to select the top-\(k\) policies from several candidate policies using only offline logged data. Typically, the final production policy is chosen based on the online A/B tests of the top-\(k\) policies selected by OPS. SCOPE-RL supports implementations of a range of OPS methods and provides some metrics to evaluate the OPS result.
Note
This documentation aims to provide a gentle introduction to offline RL and OPE/OPS in the following steps.
Explain the basic concepts in Overview (online/offline RL) and Overview (OPE/OPS).
Provide various examples of conducting offline RL and OPE/OPS in practical problem settings in Quickstart and Example Codes.
Describe the algorithms and implementations in detail in Supported Implementation and Package Reference.
You can also find the distinctive features of SCOPE-RL here: Why SCOPE-RL?
Implementation#
Data Collection Policy and Offline RL#
SCOPE-RL overrides d3rlpy’s implementation for the base RL algorithms. We provide a class to handle synthetic dataset generation, off-policy learning with multiple algorithms, and wrapper classes for transforming the policy into a stochastic one.
Meta class#
SyntheticDataset
TrainCandidatePolicies
Discrete#
Epsilon Greedy
Softmax
Continuous#
Gaussian
Truncated Gaussian
Basic OPE#
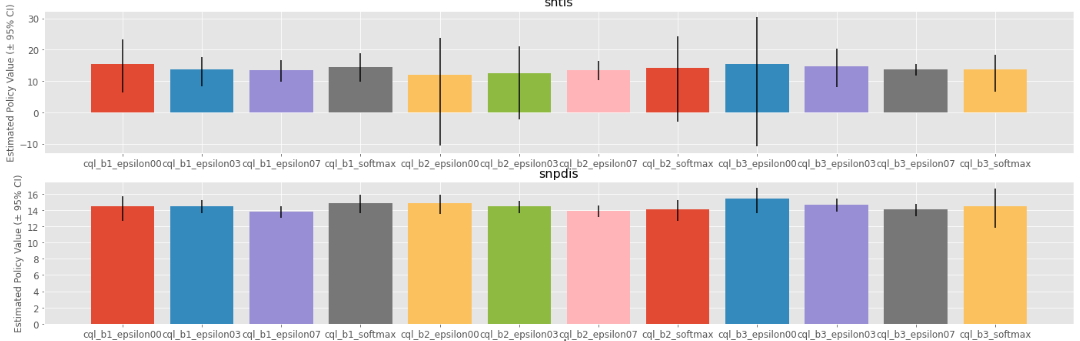
Policy Value Estimated by OPE Estimators
SCOPE-RL provides a variety of OPE estimators both in discrete and continuous action spaces. Moreover, SCOPE-RL also implements meta classes to handle OPE with multiple estimators at once and provides generic classes of OPE estimators to facilitate research development.
Basic estimators#
State Marginal Estimators#
State-Action Marginal Estimators#
Double Reinforcement Learning#
Double Reinforcement Learning [15]
Weight and Value Learning Methods#
High Confidence OPE#
Cumulative Distribution OPE#

Cumulative Distribution Function Estimated by OPE Estimators
SCOPE-RL also provides cumulative distribution OPE estimators, which enables practitioners to evaluate various risk metrics (e.g., conditional value at risk) for safety assessment beyond the mere expectation of the trajectory-wise reward. Meta class and generic abstract class are also available for cumulative distribution OPE.
Estimators#
Metrics of Interest#
Cumulative Distribution Function (CDF)
Mean (i.e., policy value)
Variance
Conditional Value at Risk (CVaR)
Interquartile Range
Off-Policy Selection Metrics#
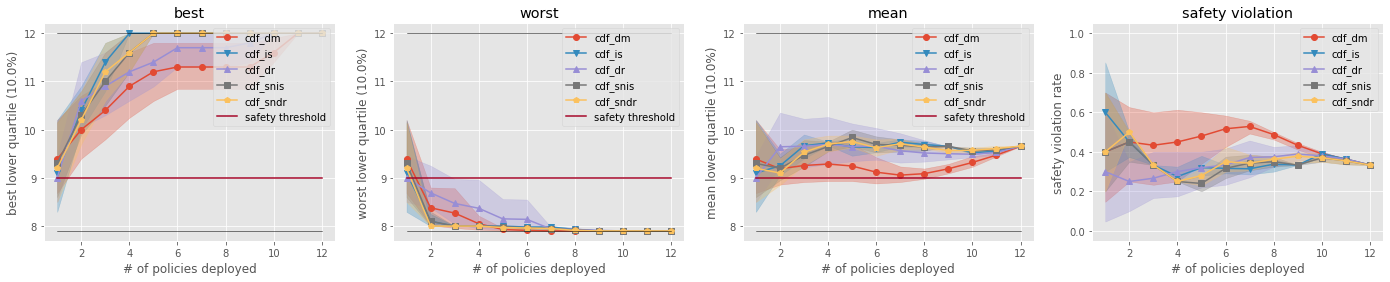
Comparison of the Top-k Statistics of 10% Lower Quartile of Policy Value
Finally, SCOPE-RL also standardizes the evaluation protocol of OPE in two axes, firstly by measuring the accuracy of OPE over the whole candidate policies, and secondly by evaluating the gains and costs in top-k deployment (e.g., the best and worst performance in top-k deployment). The streamlined implementations and visualization of OPS class provide informative insights on offline RL and OPE performance.
OPE metrics#
OPS metrics (performance of top \(k\) deployment policies)#
{Best/Worst/Mean/Std} of {policy value/conditional value at risk/lower quartile}
Safety violation rate
Sharpe ratio (our proposal)
See also
Among the top-\(k\) risk-return tradeoff metrics, SharpeRatio is the main proposal of our research paper “Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation.” We describe the motivation and contributions of the SharpeRatio metric in Risk-Return Assessments of OPE via SharpeRatio@k.
Citation#
If you use our pipeline in your work, please cite our paper below.
@article{kiyohara2023scope,
title={SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation},
author={Kiyohara, Haruka and Kishimoto, Ren and Kawakami, Kosuke and Kobayashi, Ken and Nakata, Kazuhide and Saito, Yuta},
journal={arXiv preprint arXiv:2311.18206},
year={2023}
}
If you use the proposed metric (SharpeRatio@k) or refer to our findings in your work, please cite our paper below.
@article{kiyohara2023towards,
title={Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation},
author={Kiyohara, Haruka and Kishimoto, Ren and Kawakami, Kosuke and Kobayashi, Ken and Nakata, Kazuhide and Saito, Yuta},
journal={arXiv preprint arXiv:2311.18207},
year={2023}
}
Google Group#
Feel free to follow our updates from our google group: scope-rl@googlegroups.com.
Contact#
For any questions about the paper and pipeline, feel free to contact: hk844@cornell.edu
Contribution#
Any contributions to SCOPE-RL are more than welcome! Please refer to CONTRIBUTING.md for general guidelines on how to contribute to the project.
Table of Contents#
Getting Started:
Online & Offline RL:
Off-Policy Evaluation & Selection:
- Overview
- Supported Implementation
- Create OPE Input
- Basic Off-Policy Evaluation (OPE)
- Direct Method (DM)
- Trajectory-wise Importance Sampling (TIS)
- Per-Decision Importance Sampling (PDIS)
- Doubly Robust (DR)
- Self-Normalized estimators
- Marginalized Importance Sampling Estimators
- Double Reinforcement Learning (DRL)
- Spectrum of Off-Policy Estimators (SOPE)
- High Confidence Off-Policy Evaluation (HCOPE)
- Extension to the Continuous Action Space
- Cumulative Distribution Off-Policy Evaluation (CD-OPE)
- Evaluation Metrics of OPE/OPS
- Visualization Tools
Our Proposal:
Sub-packages:
Package References:
See also: